這個編譯器筆記單純只是為了過考試而寫的,如果你真的想學編譯器,請轉到以下渠道:
其實之前就有學長做過共筆了,照理來說我編輯就在那裡就好,但我覺得自己從頭做還是會更有印象哈哈 xD
教材用的是龍書,整個學期的大綱大致為:
- 詞法分析(Lexical Analysis)
- 正規語言
- 正規表達式
- 狀態變遷圖
- 自動機
- 轉換
- 語法分析(Syntax Analysis)
- 上下文無關文法
- 下推自動機
- 自頂向下剖析(Top-Down Parsing)
- 自底向上剖析(Bottom-Up Parsing)
編譯器基礎
編譯器的四大階段
就是把一個語言轉換成另一個語言的「翻譯器」,但過程中嚴格地遵守兩者的語法,如有錯誤則會報錯。基本上就是這樣。TeX, SQL Compiler, Preprocessor 都算是編譯器。
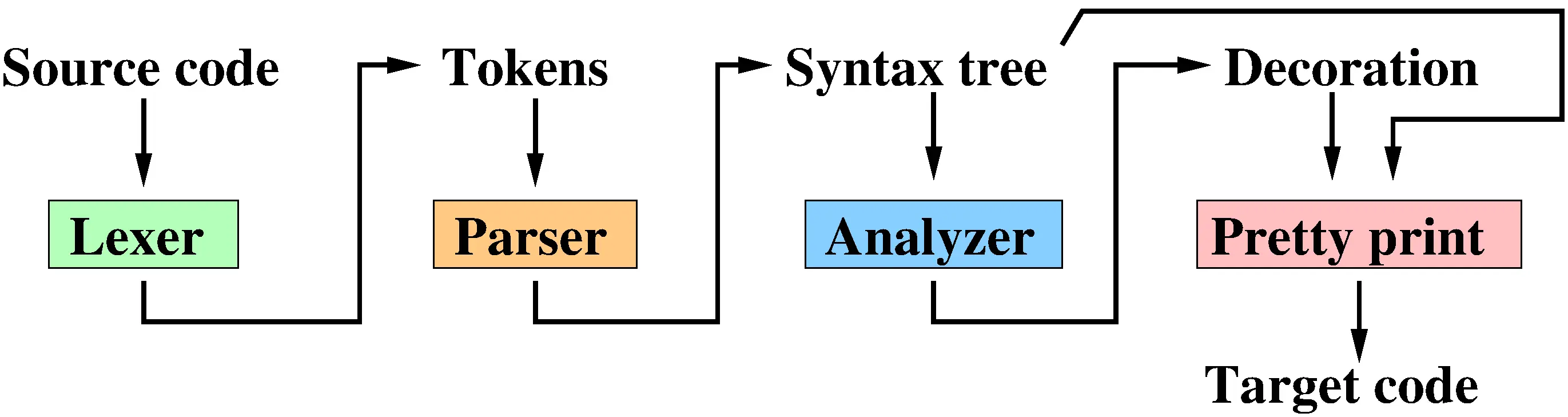
- 詞法分析器(Lexer)將原始程式碼拆解為一串詞元(Token)。詞元是程式的最小語法單位,包括分隔符號、算術運算子、關鍵字與識別子等。若將程式比擬為一本書,詞元就相當於其中的單字。
- 語法分析器(parser)則將這串詞元轉換成一棵抽象語法樹 (Abstract Syntax Tree, AST) ,以方便我們進行遍歷與分析。
- 組譯碼生成(Assembly Code Generation)階段會將抽象語法樹(AST)轉換為組合語言。在此階段,我們仍以編譯器可理解的資料結構來表示組合語言指令,而非直接輸出為純文字。
- 程式碼生成(Code Generation)階段則負責將組合語言程式碼寫入檔案,以便交由組譯器(assembler)與連結器(linker)進一步處理,最終產生可執行檔。
詞法分析(Lexical Analysis)
詞法分析器的作用就是線性地識別每個單字,把原始碼中的字元序列切分成一個個詞元,並為其標上標籤。像是遇到 if 時,詞法分析器會識別其語義為關鍵字,並標記為 if 類型;遇到 13 或 27 時,則識別其語義為整數常數,標記為 integer 類型。每個詞彙一定都會有對應的語義與類型標籤。
正規語言(Regular Language)
語言必定有字母,一串字母也可組成句子。要判斷一個句子是否合法,有兩種可靠的方式:
- 給一個演算法,看這個句子能否能組成符合該語言的合法詞元串
- 給一個可以產生該語言所有合法句子的語法
假設語言 和 ,以下是對於語言合法的操作:
- :新的語言集合
- :在大寫字母後方接上數字
- :所有四個大寫字母的句子
- :所有 可能組成的句子,其中包括空句子
- :所有 可能組成的句子,不包括空句子
正規語法(Regular Grammar)
語法必須要有四大元素:
- :非終端符號(Nonterminal Symbol)
- :終端符號(Terminal Symbol)
- 其中 ()
- :Productions,也就是符號間的轉換
- :起始符號(Start Symbol)
習慣上非終端符號會用大寫字母表示,而終端符號則用小寫。
推導(Derivation)
- 若 且 ,則 。
- 若 ,則可寫為
- 一個由語法 產生的語言 符合 規則,即:
- 字串 必須完全由終端符號組成
- 字串 必須由起始符號出發,並經由一系列推導獲得
- 若兩個語法 , 相等的,則
正規表達式(Regular Expression)
若要把語言換成正規表達式,首先幾個符號需要講清楚。每一個表達式 都代表一個語言 。比方說如果表達式為 ,那麼它代表的語言就是 。字母表使用 表示,任何字母表中的字元()都是一個正規表達式。
操作的話,正規表達式也可以完整的轉換:
- 得到
- 得到
- 得到
- 得到
我們也可以定義正規表達式,比方說 ,那麼就可以用 表達。
狀態變遷圖(State Transition Diagrams)
只靠當前狀態,推測下次合法的狀態有哪些,比方說:
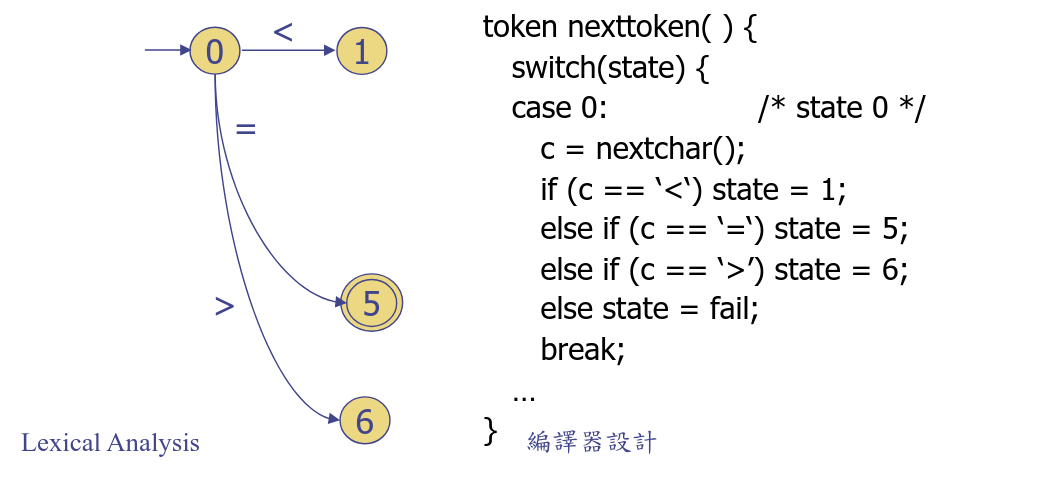
而我們可以根據其狀態特性,用 switch 程式來表示狀態變遷圖:
token nexttoken( ) {
switch(state) {
case 0: /* state 0 */
c = nextchar();
if (c == ‘<‘) state = 1;
else if (c == ‘=‘) state = 5;
else if (c == ‘>’) state = 6;
else state = fail;
break;
...
}
}
自動機(Automata)
如果下個接收的字元不符合任何下個預期的狀態,那麼直接回傳 “No”,持續檢測直到結束,就回傳 “Yes”。
有限自動機和有限狀態機的區別
有限自動機和無限自動機的區別
用更明確的定義:
- :一個有限、非空的狀態集合
- :字母表
- :狀態轉移關係的集合,,表示在狀態 看到 往狀態 跑。
- :起始狀態
- :結束狀態的集合
若這些狀態中,沒有一個是 -transition,且在每個狀態 時遇到輸入 ,最多只有一邊可以離開 狀態,若滿足上述情況,稱之為確定性有限自動機(Deterministic Finite Automaton)。否則即為不確定性有限自動機(Nondeterministic Finite Automaton)。
確定性有限自動機(Deterministic Finite Automaton, DFA)
DFA 的程式碼非常簡單:
s = s0
c = nextchar();
while (c != eof) do
s = moveto(s, c);
c = nextchar();
end
if (s is in F) then
return “yes”
else
return “no”
也就是 。
不確定性有限自動機(Nondeterministic Finite Automaton, NFA)
NFA 因為有 的情況,因此會改成 。以下是 NFA 的虛擬碼:
// NFA
S = epsilon_closure(s0);
c = nextchar();
while (c != eof) do
S = epsilon_closure(move(S, c));
c = nextchar();
end
if (S ∩ F != ∅) then
return "yes";
else
return "no";
// epsilon_closure(T)
push all states in T onto stack;
initialize epsilon_closure(T) to T;
while (stack is not empty) do
t = pop stack;
for (each state u with an edge from t to u labeled epsilon) do
if (u is not in epsilon_closure(T)) then
add u to epsilon_closure(T);
push u onto stack;
end if
end for
end while
其實 epsilon_closure 在做的就是「把所有不需要輸入字元的狀態都蒐集起來」放到下次考慮,這就叫做「空轉移」。雖然從虛擬碼來看,感覺 DFA 比 NFA 簡單,但其實 NFA 的圖看起來會更直覺。
以下圖簡單舉例 NFA 的轉換:
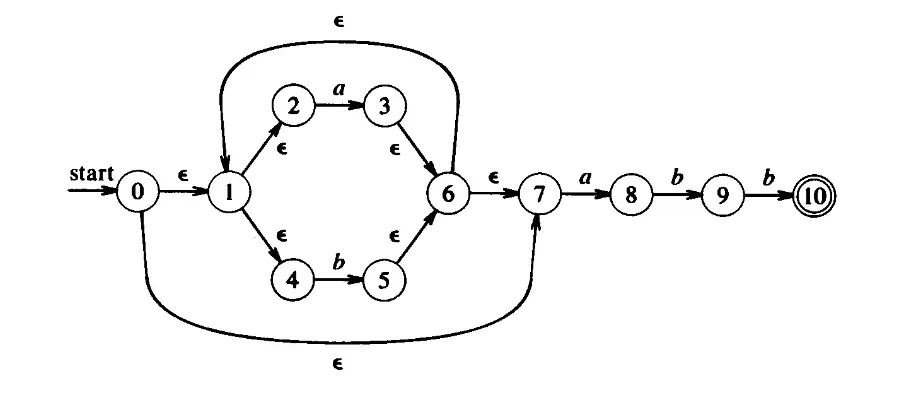
epsilon_closure(0)= {0, 1, 2, 4, 7}move(A, a)=epsilon_closure({3, 8})= {1, 2, 3, 4, 6, 7, 8}
轉換
根據 Kleene’s Algorithm,正規表達式和狀態變遷圖之間是絕對可以轉換的,因為這兩者都是在描述正規語言。
NFA 轉換成 DFA
通常因為 NFA 的規則更少,建構起來也更簡單,所以如果要建構 DFA,通常也會先從 NFA 開始。其實要把 NFA 換成 DFA 也很簡單,每次 NFA 都會從「一個狀態集合」開始檢驗,也就是 epsilon_closure 的結果,我們幫每個獨特的狀態集合都命個名,讓每個狀態都是特殊的狀態,最後再動一下就可以換成 DFA 了。
同一張圖重講一次。最開始 epsilon_closure(0) = {0, 1, 2, 4, 7} ,而後 move(A, a) = epsilon_closure({3, 8}) = {1, 2, 3, 4, 6, 7, 8} 。這時如果是 move(B, a),那麼其結果依然是 epsilon_closure({3, 8}),也就是一樣可以用 來取代。
依樣畫葫蘆,就可以得到新的圖:
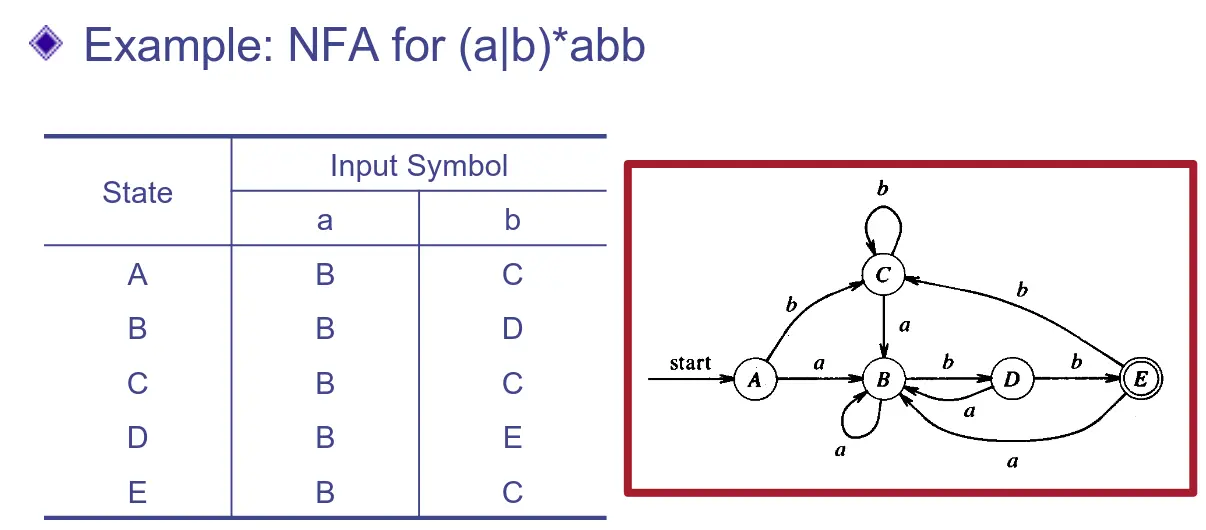
但看起來 … 還是有點丑。看看 和 ,咦?這兩個是不是有點像?若輸入 就轉移到 ,直到輸入 就會轉移到 !所以這兩個其實也是一樣的,但是剛剛居然漏掉了!
藉此我們可以發現,透過上述方法簡化後的結果並不一定是最少狀態的最佳結果。我們可以透過分類起點與終點,比較兩者間的狀態轉移來分類。假設分開的兩個狀態之狀態轉移居然一致,那就表示裡面各有一個狀態是可以合併簡化的。
在這個例子中,把他們切成 (ABDE)(C) 兩個狀態,可以發現兩者透過 的狀態轉移後都會到 C 狀態,因次必各有一個狀態可以合併。如果分 (ABCD)(E),則前者 轉到 E,後者 轉到 C,因此就不同,故之後 ABCD 還可以再繼續分,直到最後 (A)(C) 發現居然是一樣的。那就表示 A 和 C 可以合併。於是最後變成了這樣:
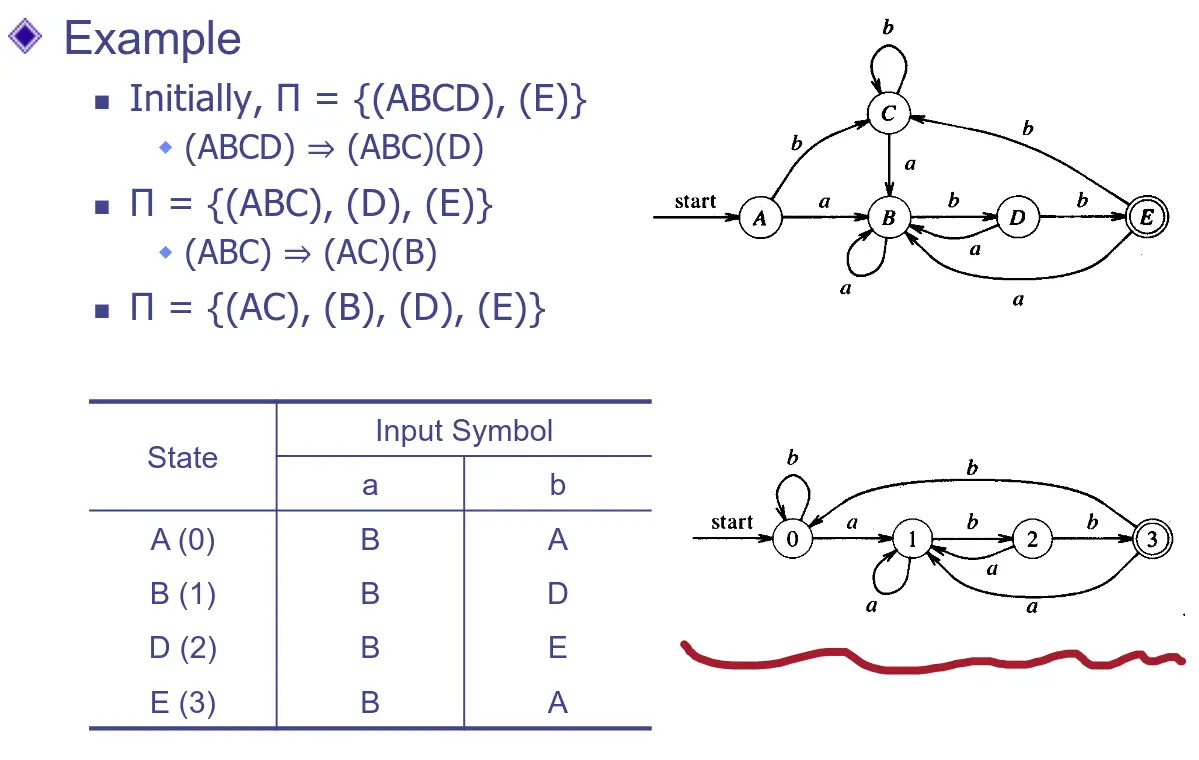
正規表達式轉換成 NFA
有種叫做湯普森構造法的方法可以快速簡化,維基百科裡頭的圖就寫得很清楚了,但舉個例子可能更清楚。一樣是用上圖舉例,那其實就是 (a|b)*abb 的正規表達式:
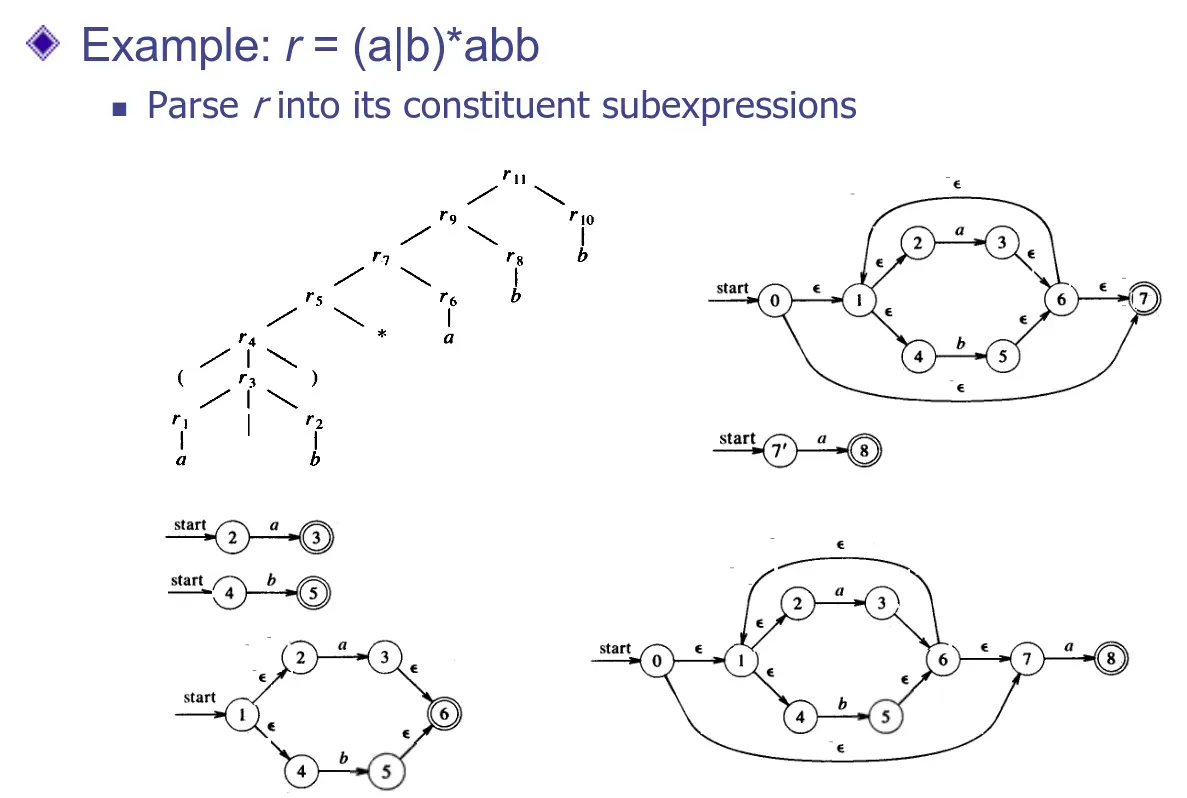
NFA 轉換成正規語法
正規語法不等於正規表達式
- 為每個狀態 建立一個非終端符號
- 若狀態 讀取符號 後轉移到狀態 ,則
- 若狀態 讀取符號 後轉移到狀態 ,則
- 若狀態 為終端符號,則
- 若狀態 是起始狀態,則 為起始符號
完成上述步驟即可建構完整的 。
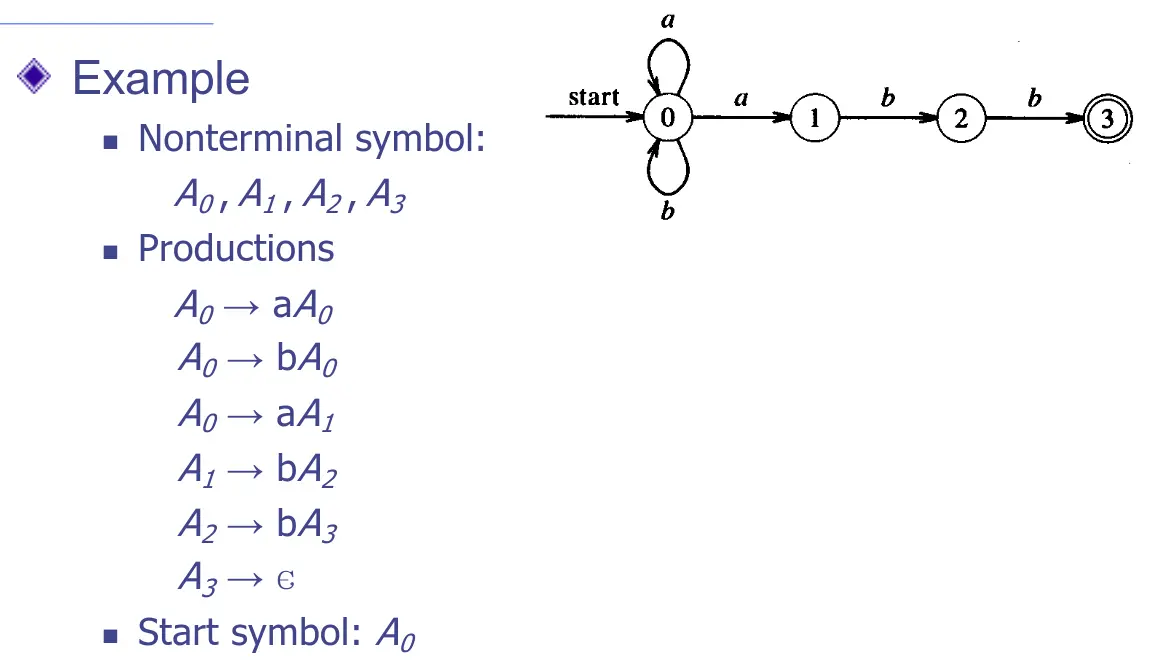
正規語法轉換成 NFA
自己看 ;),可不要忘了這裡是部落格,不是正統教材:

語法分析(Syntax Analysis)
當詞法分析器完成詞元翻譯後,剖析器會根據這些詞元建構出詞彙間的邏輯結構。在 Tiny Compiler 中採用 BNF(巴科斯範式)來處理計算:
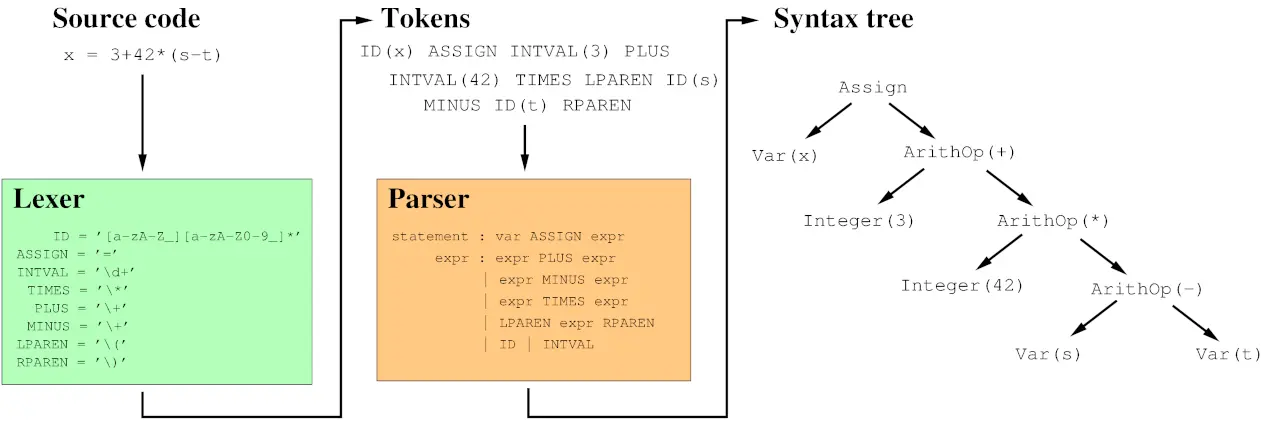
以下是一個簡單的推導例子:
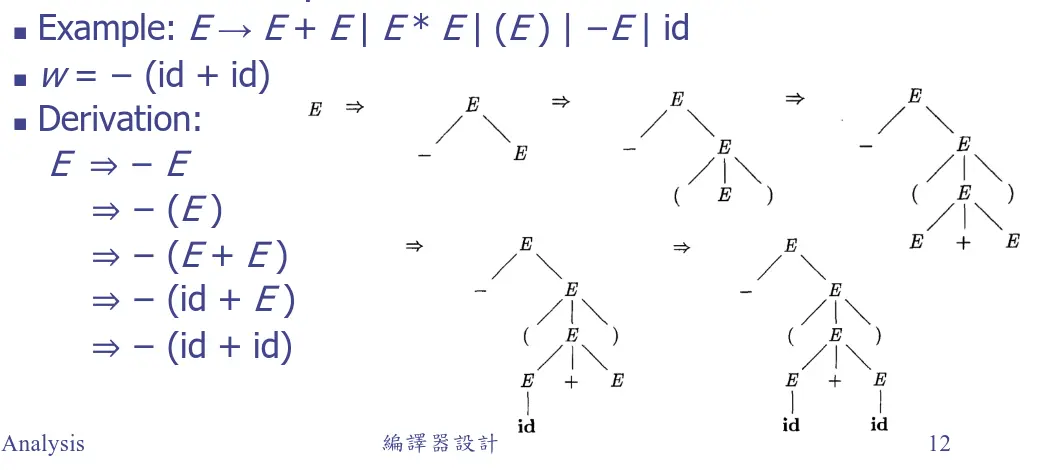
上下文無關文法(Context-free Grammar)
為什麼需要學上下文無關文法?
因為正規語言的表達能力有限,有些架構無法處理,例如 。我們可以利用泵引理來反證。
上下文無關文法可以這麼定義:
要證明能否使用正規語言表示其實很簡單,如果能畫出 NFA,那就是合法;如果不行,請用泵引理(Pumping Lemma)反證:
泵引理的原理其實很簡單。想像一下,機器若只有 個狀態,假設字串長度 ,那麼必定有個狀態會被重複使用,這其實就是鴿巢原理,因此在字串處理的路徑上,必定出現迴圈。因此推定,只要給定的 夠長,那有限狀態機(NFA 或 DFA)裡就會有迴圈。換句話說,當我們選到一個長度大於等於 的合法字串 時,這個定理保證在 最前面的 個字元範圍內,絕對可以找到一段無限重複的片段 。
下推自動機(Pushdown Automata)
在原有的有限狀態機之外,允許狀態機將狀態和符號推入堆疊(Stack)上保存。以此就能表達諸如 或 的語言。
下推自動機的定義為 ,其中:
- :有限的狀態集合(Finite set of states)。
- :輸入字母表(Input alphabet)。
- :推疊字母表(Pushdown alphabet),即存放在堆疊中的符號。
- :轉移函數(Mapping),定義了機器的運作規則。其映射關係為 。
- :初始狀態,且 。
- :初始的推疊符號,且 。
- :最終狀態的集合(Set of final states)。
畫表、畫圖就這樣畫,詳細可以參考維基百科:

剖析器通常選擇兩種順序剖析詞元,分別是 Top-Down 和 Bottom-Up,以下會詳細介紹兩者的情境與優劣。
自頂向下剖析(Top-Down Parsing)
就是從輸入的字串尋找最左推導(Leftmost Derivation)的過程,也就是說,在建構剖析樹時,是從樹的根節點起始符號開始的,並以 preorder 的方式依序向下建立所有的子節點。
左遞迴和左因式分解
然而,此法在以下兩種情境會產生問題:
左遞迴
當非終端符號不斷地重複出現在推導的最左端,就會產生左遞迴,比方說 。而解決左遞迴的解決方法,就是不要讓它左遞迴 :)。舉個例子,以後遇到就套同個模板進去:
其實思路很簡單,照原本的勢頭, 最後肯定會在最左邊,那我就先讓它直接先在那裡就定位,之後再用一個佔位符 替代,不斷地把後面的 補齊。什麼?你說很簡單?來舉個例子練習一下:
好啦,其實就先把 後面的順序化簡成 ,再令 ,代進去就會變成 ,接著依樣畫葫蘆就可以了。
左因式分解
直接舉例比較直觀,假設我們有:
兩條規則。當剖析器遇到了 ,且知道下個符號是 if,這時它有兩個選擇,但它不知道哪個是對的,除非它把整句都剖析完,然其機制不允許它這麼做,這就是角色困難。解決方法,一樣是就不要讓它發生 ;),也就是先直接把這些規則的共同前綴提前提取出來,接著用新的非終端符號替代就可以了。所以改寫後的文法會變成:
- ( 代表空字串,也就是原本沒有
else的情況)
Generalize 就是:
FIRST & FOLLOW
想像一個情境:
你輸入了 ,讀到 時剖析器就會發現 有兩條規則可以選,必須要全部確認完才可以回報錯誤。在這個例子中,若先進入了 ,則剖析器就必須回朔把剛剛建的語法樹局部刪除。這樣就非常麻煩,而且很浪費時間。我們希望只要一遇到不符規則的情況,就能夠直接回報錯誤。
所以他們想出了一個牛逼的辦法,假設已經左因式分解了所有規則,那麼肯定每個規則在一個共同前綴後,就必定有一個詞元是不同的,這時我只要先偷看下個詞元是什麼,就可以避免走錯路了!
實現的核心就是透過偷看 Lookahead 決定使用哪條規則,我們透過計算 FIRST & FOLLOW 來達成此目的:
FIRST
FIRST() 表示所有從 堆導出的字串中,開頭可能出現的所有終端符號之集合,套用以下規則即可:
- 若 為終端符號,則 FIRST() =
- 若 ,則新增 到 FIRST() 內
- 若 ,則:
- 若 到 都能推導出空字串 ,那 的開頭符號就可能成為整個 的開頭字串,因此需將其加入 FIRST() 中。寫成數學就是
- 若所有 到 都能推導出空字串 ,那就把 加入 FIRST() 內,寫成數學就是
FOLLOW
所有可能「緊接在非終端符號右邊」的終端符號,反覆套用以下三個規則:
- 務必先把代表結束的 記號加入 FOLLOW()
- 若 ,就把 FIRST() 裡除了 以外的所有符號加入 FOLLOW()
- 繼承:
- 若 ,則將 FOLLOW() 所有內容加入 FOLLOW()
- 若 ,且 FIRST(),則同樣把所有 FOLLOW() 的內容加入 FOLLOW()。
簡單的範例如下:

FIRST 蠻直觀的,FOLLOW 以 FOLLOW() 舉例一下。首先加入 $,再來加入 FIRST(),也就是 *。最後處理繼承,因為 ,因此加入 FOLLOW() 的所有內容,所以結果就是 {+, *, ), $}。
預測解析表(Predictive Parsing Table)和 LL(1)
當上述情況皆處理完畢,就可以試著填寫預測解析表了,無腦填就對了啦。
- FIRST: 找出 FIRST() 裡面的所有終端符號 ,把推導 填入表格的 欄位裡頭
- FOLLOW:若 ,則去查看 ,並且對於 中的每個終端符號 ,將推導 填入表格的 欄位裡頭
用同樣的題目來當例子:

FIRST 都蠻直覺的,主要看 的部份。以 FIRST() 舉例,因為裡面包含 ,表示 ,所以要去查 FOLLOW(),接著就依樣化葫蘆,填入 和 就好了。
如果這個過程中,解析表沒有任何一個欄位有多重定義,那麼恭喜!這個語法就成了最讚的 LL(1) 語法啦!當別人一口炸雞一口可樂的時候,你一個堆疊一張表就可以剖析所有詞元了 :D。
快速判別是不是 LL(1)
規則多只限制在同個非終端符號的分支上,不同非終端符號基本不管。
- 每個分支開頭字元絕對不能一樣
- 最多只能有一個分支可以推導出空字串
- 能消失的分支的非終端符號之 FIRST 和 FOLLOW 不能一樣
Nonrecursive Predictive Parser
走過一次完整的流程:

語法錯誤處理
分成四點,直接從 LLM 複製貼上:
- 恐慌模式(Panic mode):最簡單也最常用。發生錯誤時,不斷丟棄輸入的符號,直到遇到「同步記號(Synchronizing tokens)」(例如分號 ; 或 end)為止
- 片語層級修正(Phrase level):對剩餘輸入進行局部小幅度的修正,例如把逗號替換成分號,或是補上漏掉的分號
- 錯誤生成規則(Error production):事先在文法中加入能產生常見錯誤寫法的生成規則,一旦匹配到就報錯
- 全域修正(Global correction):以最少的修改次數(最少的字元插入、刪除或修改)來修正整個輸入字串
課堂教的就是恐慌模式。恐慌模式的精隨即在於,若遇到錯誤,則剖析器將不斷捨棄接下來的所有輸入,直到遇到預先定義好的同步記號(Synchronizing Tokens)為止。至於什麼是同步記號呢?就是指那些有超高辨識度且沒有意義的符號,比方說 ;。FOLLOW() 和 FIRST() 的集合也算喔!各有原因,但我懶得寫,所以留給讀者當做練習。
處理情況分兩種:
- 如果是同步記號,那就把堆疊最頂端的符號彈出,直到符合為止。
- 如果不是同步記號,那就直接讓它滾啦!我是說,直接當作沒看見這個輸入。
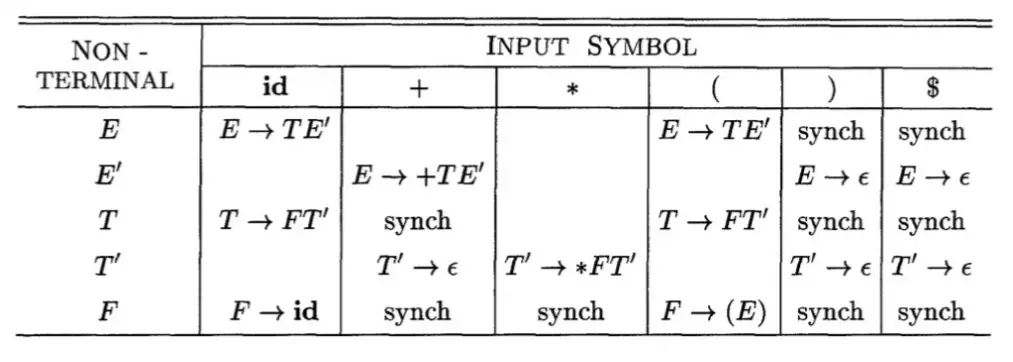
建議在表上把同步記號畫出來,比較好判別。
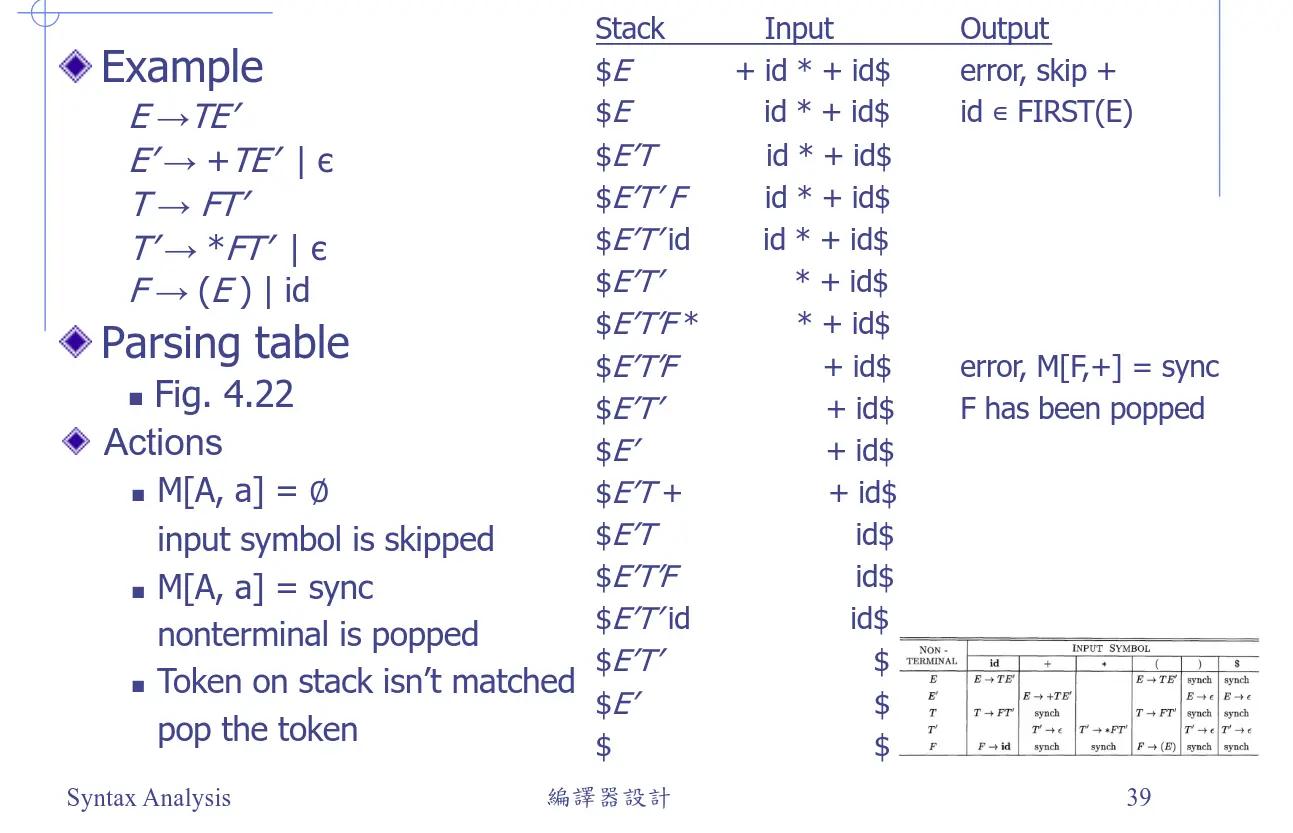
自底向上剖析(Bottom-Up Parsing)
原本我們都是從推導的左到右,試著從樹的根節點起始符號開始建構。但自底向上反過來,反向的最右推導(Rightmost Derivation in Reverse),我們要從葉節點反推回到根節點去,就是把一個字串 還原成起始符號啦。
移位-還原剖析(Shift-Reduce Parsing)

可以看到,例子中有些地方可以選擇 shift 或 reduce,且結果都是沒問題的。
剖析衝突(Shift/Reduce Conflict & Reduce/Reduce Conflict)
但不是每次都這麼幸運,有時候其中一種才是正確的。可能有兩種狀況:
Shift/Reduce Conflict
- 不知道要移位還是還原
- and
- Dangling else
Reduce/Reduce Conflict
- 堆疊頂端的句柄同時符合兩條以上推導的右半邊
- and
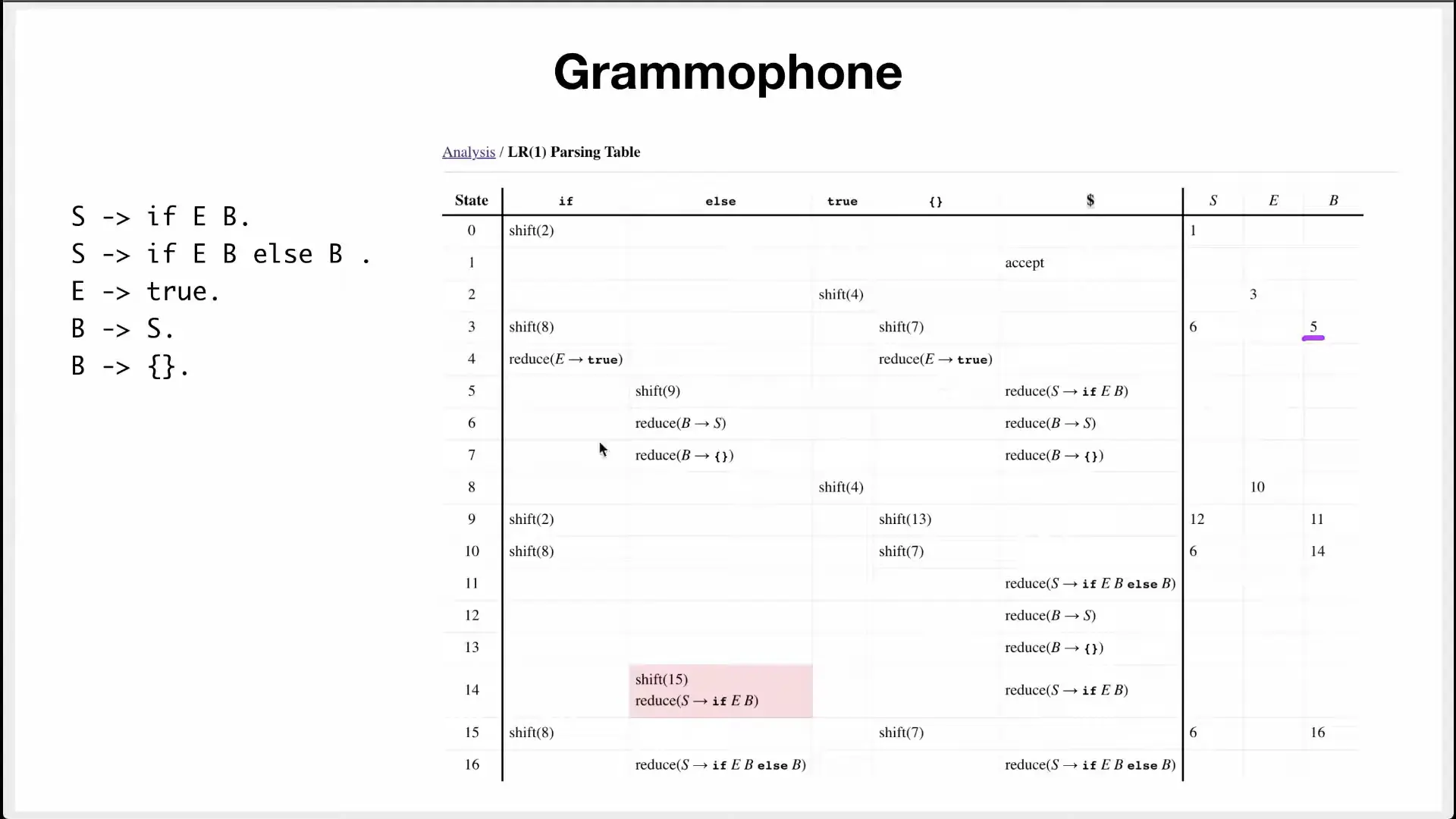
LR
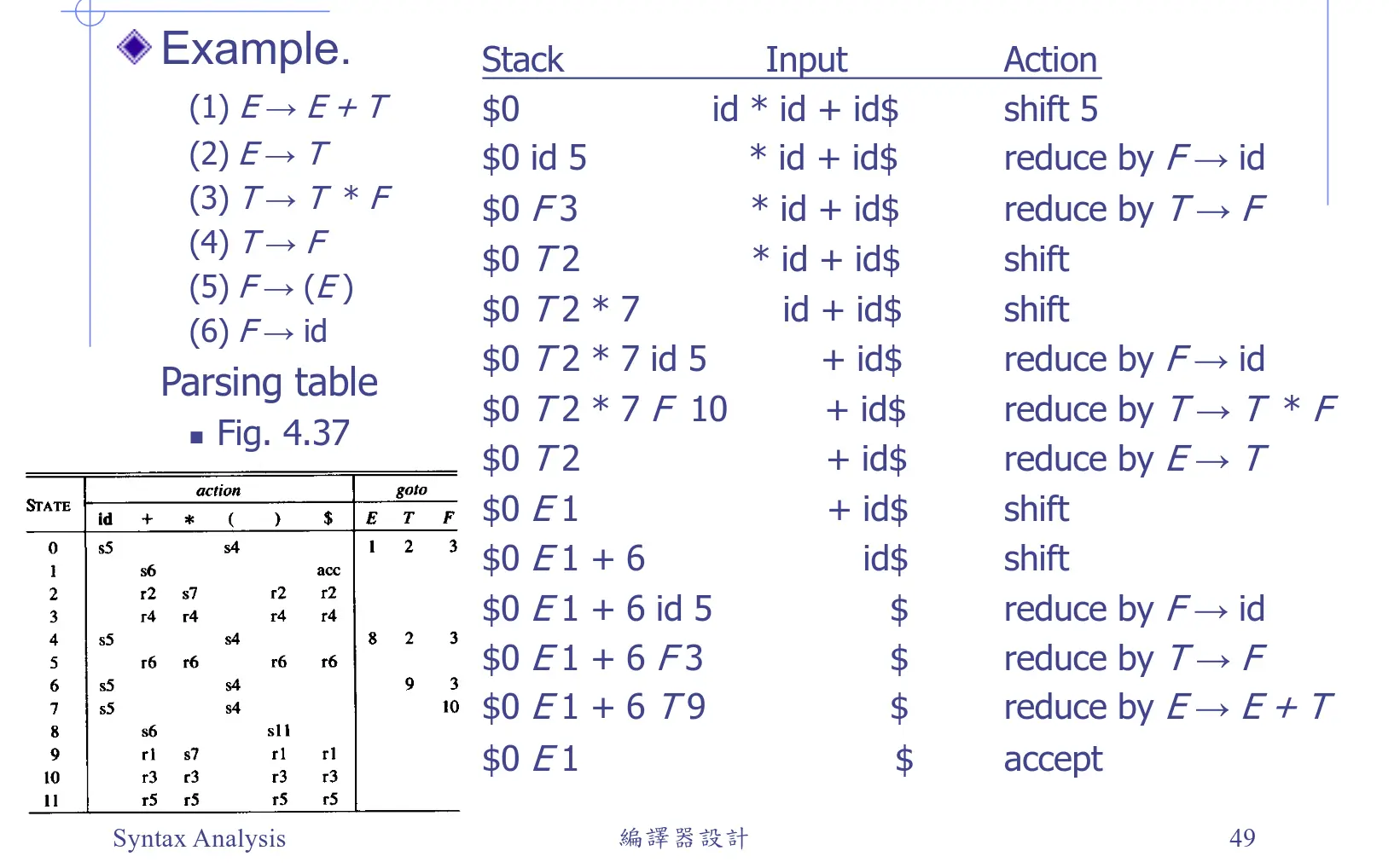
這東西是 SLR(1),老師只是用他來展示操作流程而已
看這兩行大概就懂了:
第二行:
- 堆疊:
$0 id 5 - Input(剩餘輸入):
* id + id$
當前堆疊頂端的狀態是 5,而輸入端目前看到的是 *。對照左下角的分析表,橫列 5 遇到直欄 * 的格子寫著 r6(也就是用第 6 個規則 進行歸約)。接著把堆疊頂端的 id 和狀態 5 彈出(pop),替換成非終端符號 F。此時堆疊變成 $0 F。接著查看狀態 0 遇到 F 該去哪裡,對照分析表的 goto 部分,狀態 0 遇到 F 會對應到狀態 3。所以把狀態 3 壓入堆疊,堆疊就變成了下一行的 $0 F 3。
第七行:
- 堆疊:
$0 T 2 * 7 F 10(此時最頂端狀態是 10,輸入端看到 +)
這次規則右邊有三個符號(, , ),所以我們要成對地彈出三組,也就是把 F 10、* 7、T 2 全都彈出!彈出之後,整個後面都被清空了,堆疊這時只剩下 $0。此時最頂端露出來的狀態是 0。我們要把歸約後的新符號 T 放進去。看著頂端的 0 去查 goto 表的 T 欄,對應數字是 2。把 T 和 2 壓入,變成紅框第三行的 $0 T 2。
這樣一直做就結束啦!
如果一個詞元串有多種剖析方式,那他就絕對不會是 LR 家族的成員。
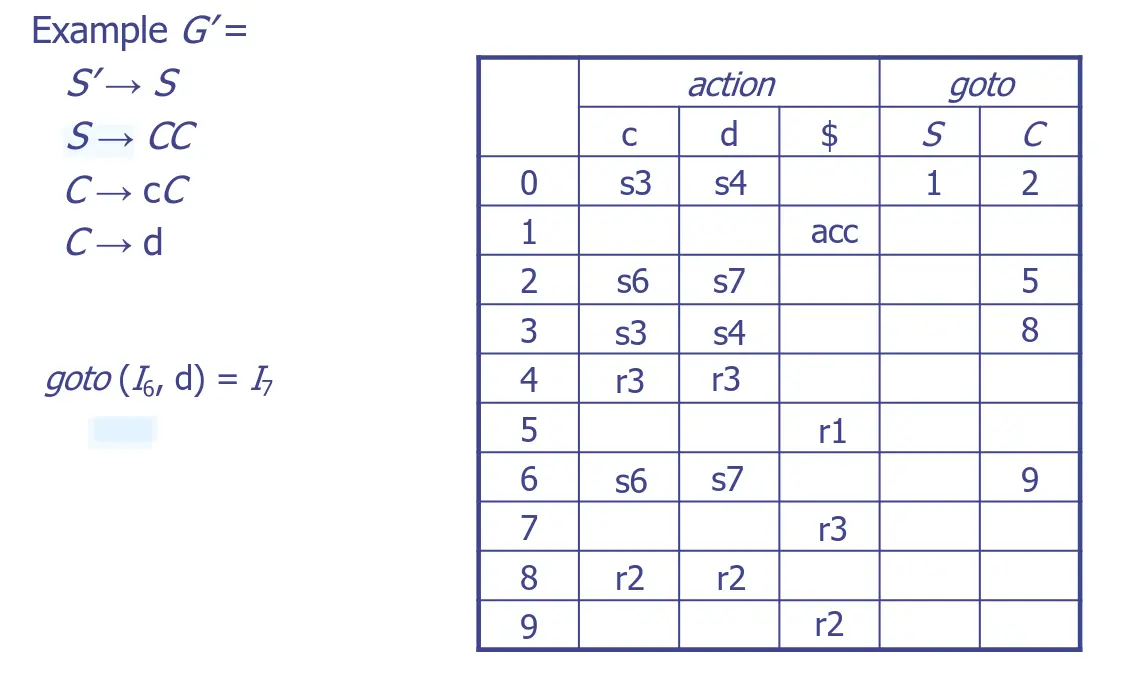
如何建構 LR(0) Table
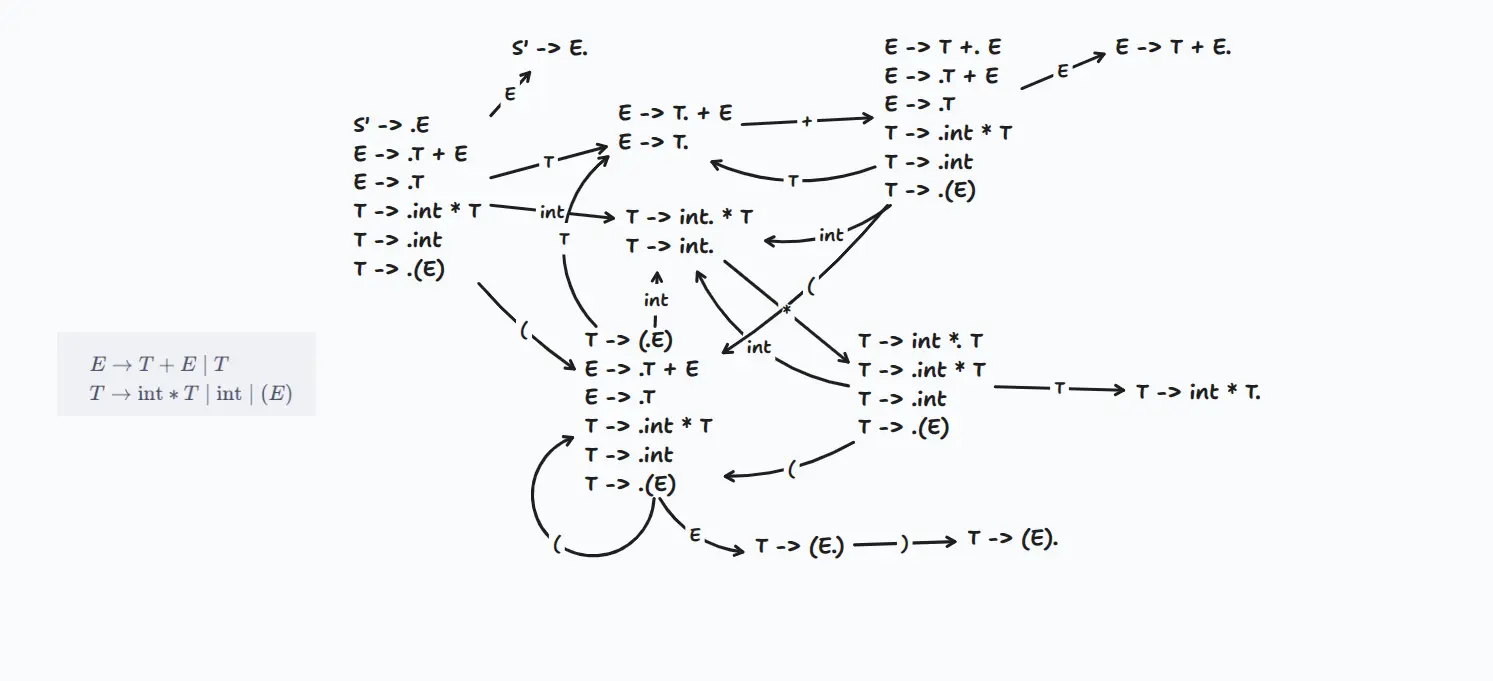
以下為某個範例:
有一個點表示現在執行到哪裡,比方說 代表我們剛看完了 和 ,正在期待看到 。先加一個新規則 ,接著其實就畫 Automata,底下從 開始看:
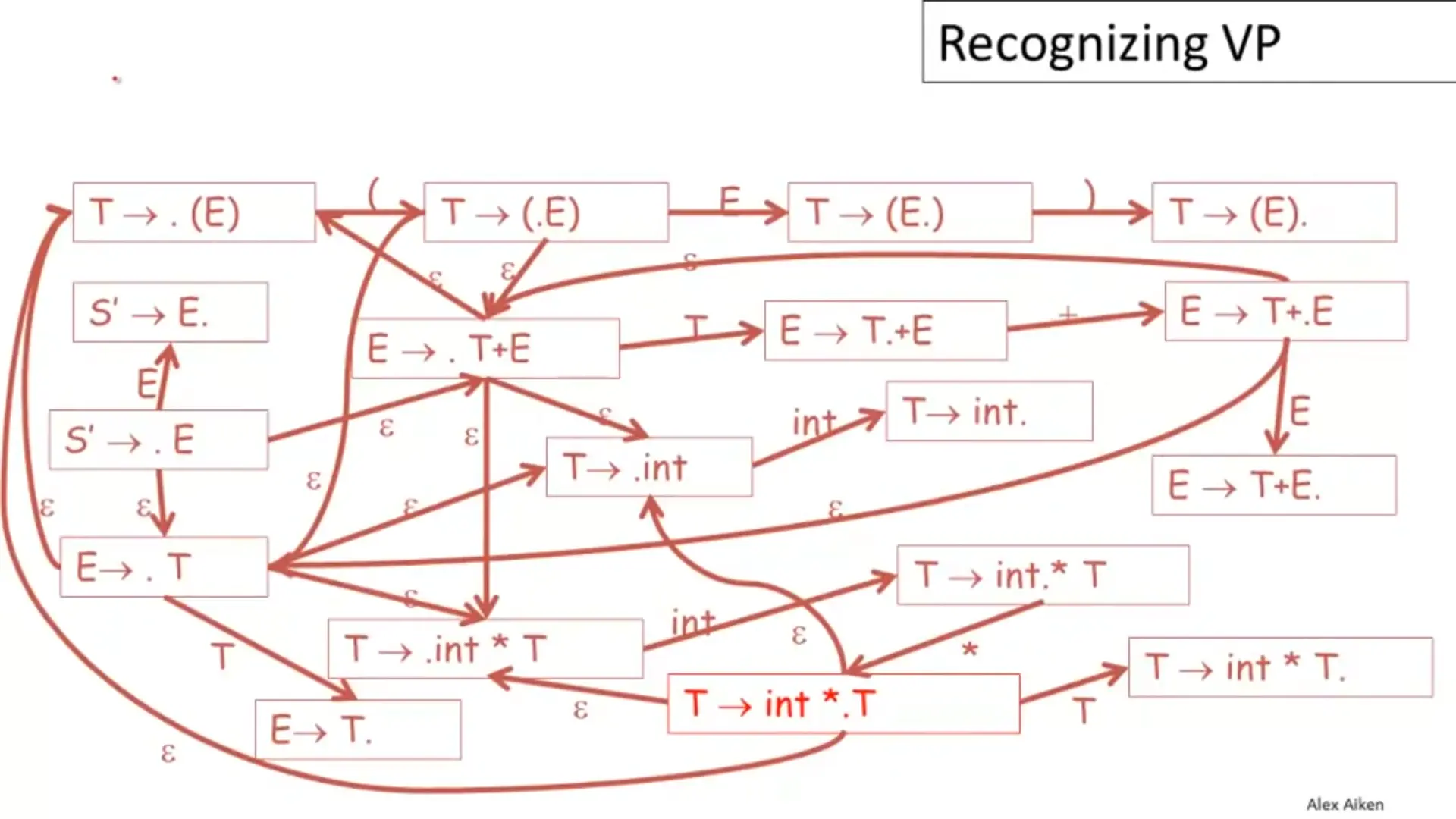
參考NFA 轉換成 DFA章節化簡以後:
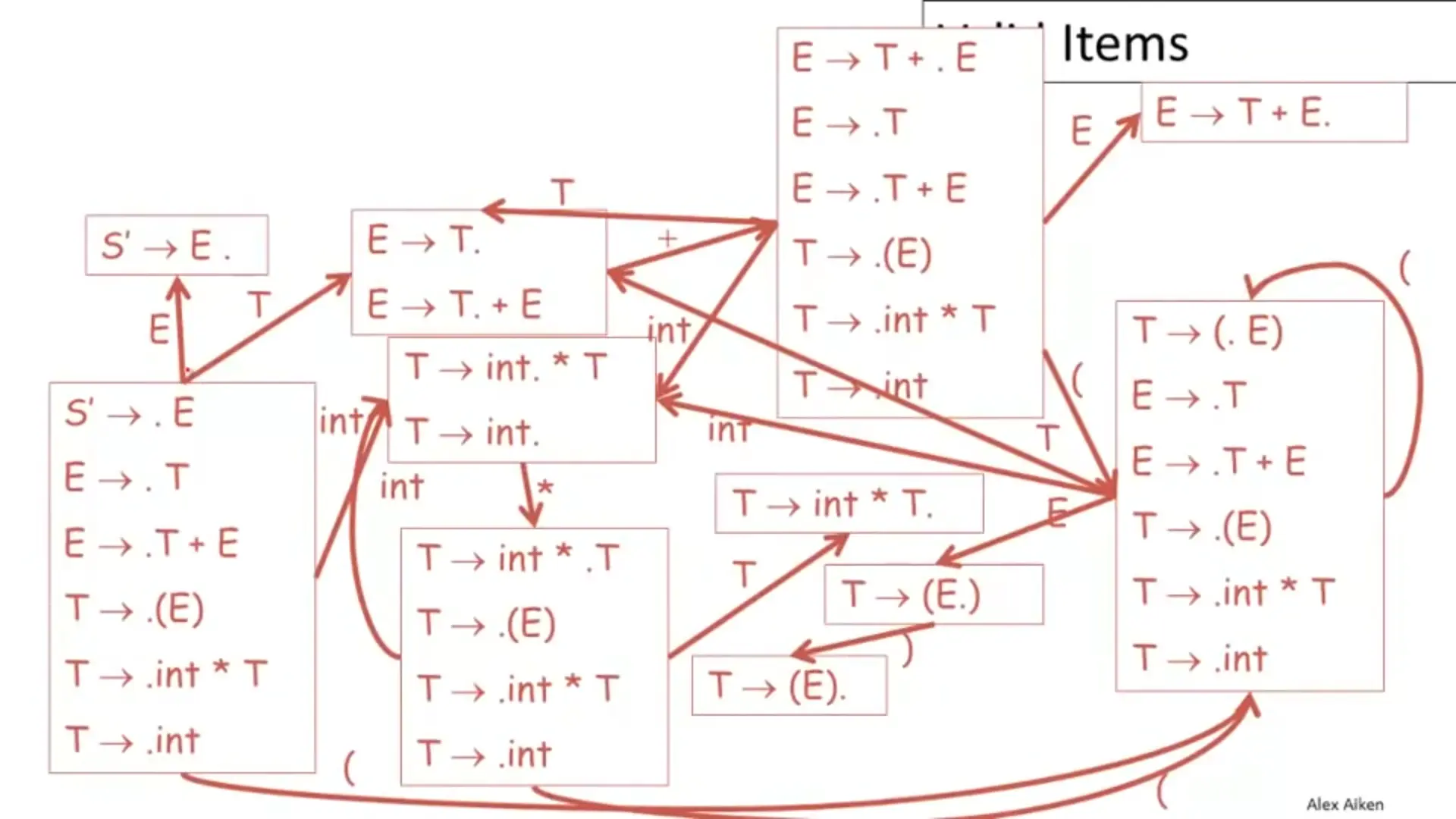
雖然可以這樣啦,但這樣實在是太麻煩了 … 所以有幾個策略:
閉包(Closure)
接著要計算閉包(Closure)。如果圓點後面緊跟著一個非終端符號,就必須把所有以該符號開頭的規則通通加進來,並且把點放在最前面。從起始符號開始看,直到結束。
比方說,一開始放入 。因為點後面是 ,所以要把 和 加進來。加進來後,發現 的點後面是 ,所以又要再把 開頭的規則加進來,以此類推,直到點後面都是終端符號為止。這整坨項目集合,就是狀態 0。
轉移(GOTO)
再來計算轉移(GOTO)。當我們在某個狀態看到一個符號(終端或非終端),我們就把圓點 往右移一格,並對新產生的集合重複做 Closure,這就會形成一個新狀態。從狀態 0 開始四面八方擴展,直到沒有新狀態產生為止。
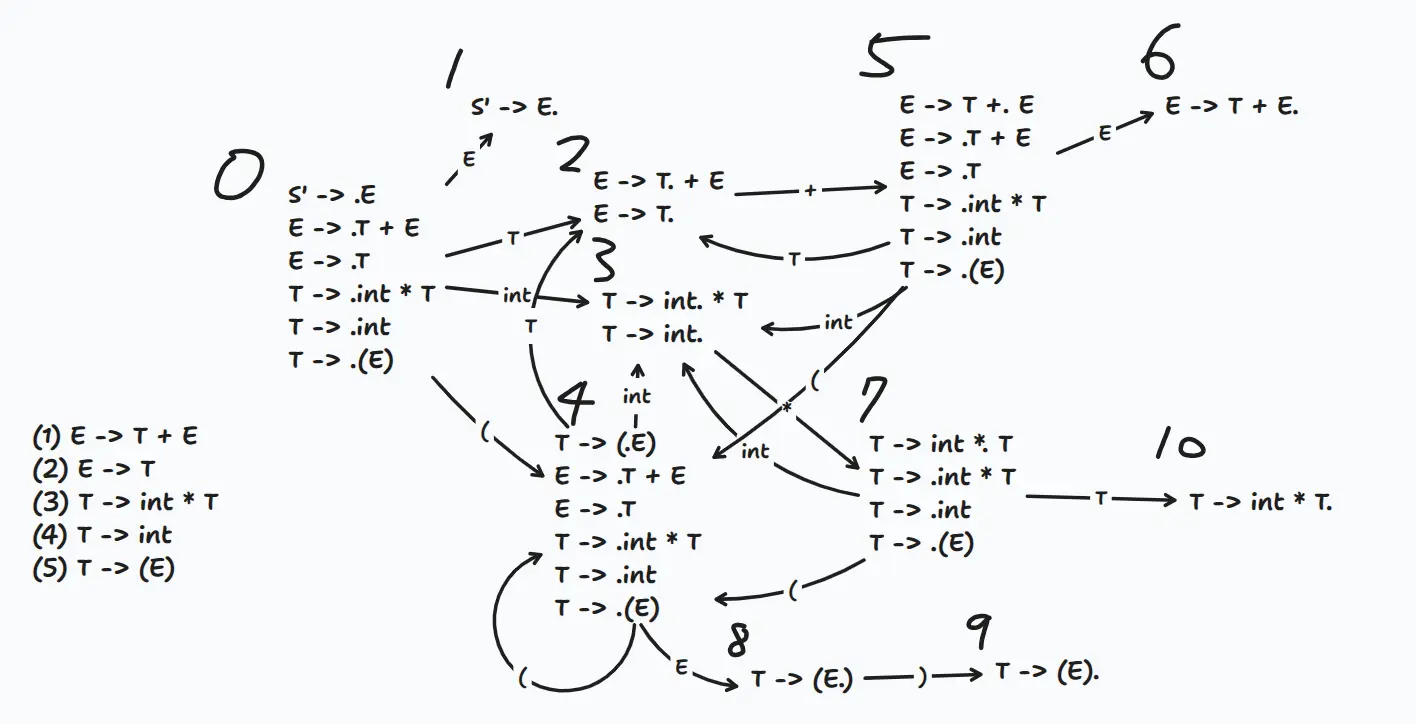
填 LR(0) 表時要注意,若遇到 Reduce,則該列的所有格子都該填上 Reduce。
| State | Action | Goto | ||||||
|---|---|---|---|---|---|---|---|---|
| int | ( | ) | + | * | $ | E | T | |
| s3 | s4 | 1 | 2 | |||||
| acc | ||||||||
| r2 | r2 | r2 | s5 / r2 | r2 | r2 | |||
| r4 | r4 | r4 | r4 | s7 / r4 | r4 | |||
| s3 | s4 | 8 | 2 | |||||
| s3 | s4 | 6 | 2 | |||||
| r1 | r1 | r1 | r1 | r1 | r1 | |||
| s3 | s4 | 10 | ||||||
| s9 | ||||||||
| r5 | r5 | r5 | r5 | r5 | r5 | |||
| r3 | r3 | r3 | r3 | r3 | r3 |
從表格很明顯就能看出有 Shift/Reduce Conflict:
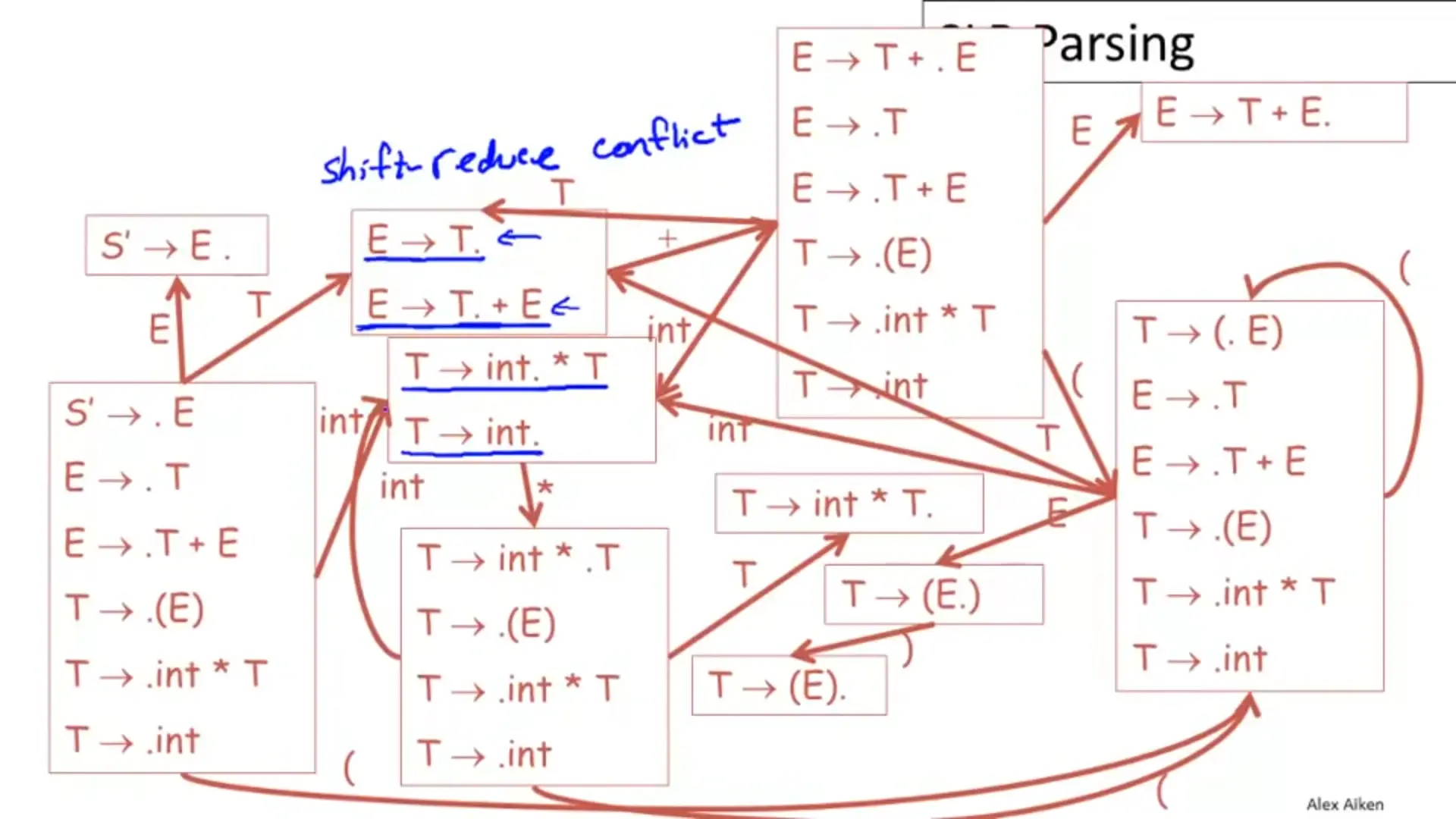
這種狀況就要透過建立 SLR 解決。
SLR(1)
- Idea: Assume
- stack contains
- next input is
- DFA on input terminates in state
- Reduce by if
- contains item
- 這裡是唯一有變化的地方
- 如果就算看了 FOLLOW 還是有歧義的話,那 SLR 也沒有辦法
- Shift if
- contains item
舉個例子,假設某個狀態包含了:
這就是 Shift/Reduce 衝突對吧!那這時我們看看 FIRST 和 FOLLOW:
- :
- :
若接下來的輸入 則 Shift,若 則 Reduce。可以看到,兩者還是有衝突!所以就算用 SLR(1) 也救不了了。
至於我們上面的例子:
- :
- :
和
- :
- :
兩者不衝突,因此其為 SLR(1)。
| State | Action | Goto | ||||||
|---|---|---|---|---|---|---|---|---|
| int | ( | ) | + | * | $ | E | T | |
| s3 | s4 | 1 | 2 | |||||
| acc | ||||||||
| r2 | s5 | r2 | ||||||
| r4 | r4 | s7 | r4 | |||||
| s3 | s4 | 8 | 2 | |||||
| s3 | s4 | 6 | 2 | |||||
| r1 | r1 | |||||||
| s3 | s4 | 10 | ||||||
| s9 | ||||||||
| r5 | r5 | r5 | ||||||
| r3 | r3 | r3 |
LR(1)
就是多加上個 LOOKAHEAD,也就是要偷看該規則若 reduce 後,後面會接上哪個符號,而若為 ,則應該繼承該條規則的 LOOKAHEAD。
當我們在一個狀態裡面把點後面緊接著的非終結符號展開時,新的規則能夠接受什麼前瞻符號,取決於原規則中該非終結符號「後面跟著什麼」。如果後面有明確的終結符號,那前瞻符號就是它;如果後面什麼都沒有,也就是你筆記裡寫的若為空字串,那展開出來的新規則就會直接繼承原本那條規則的前瞻符號。
所以同個例子的 就會長:
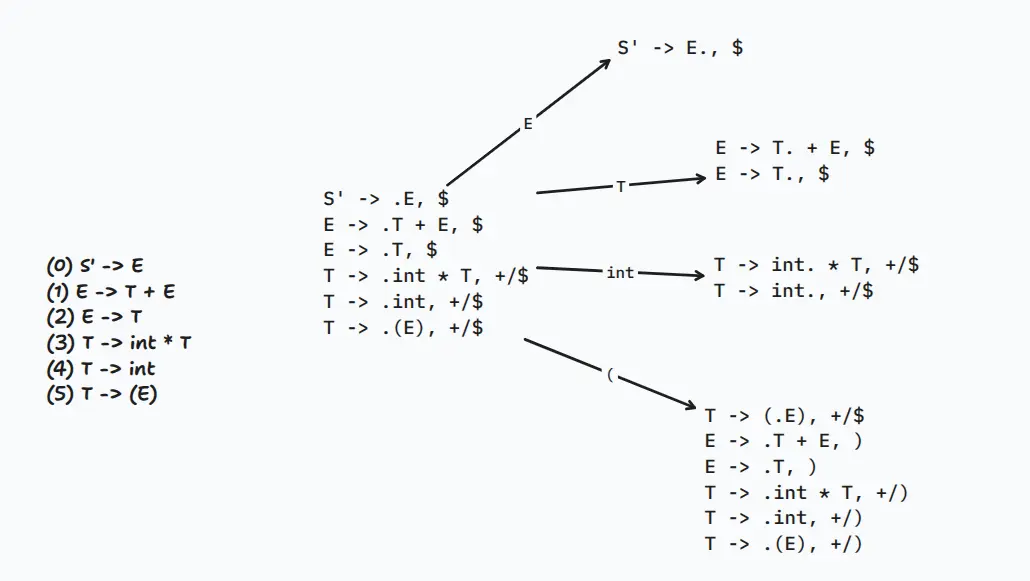
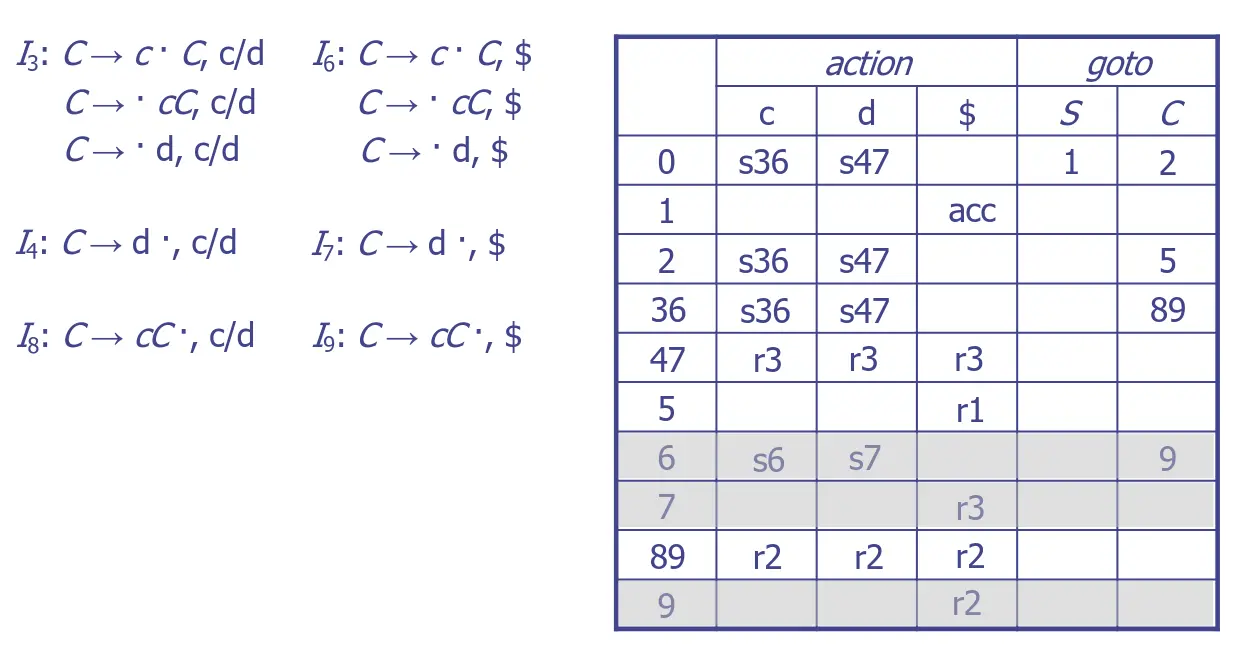
我實在懶得畫了 ._ . 因為他狀態會超多的啦!上面這個圖已經大概把坑都採過了就直接跳過啦哈哈。這就是 的問題,狀態太多了,會有狀態爆炸的問題。所以下面的 就是要解決這個問題。畫表記得 reduce 只需要填在當前推導規則的 Lookahead 就好了。
LALR(1)
為了解決狀態爆炸,他的宗旨就是:「只要兩個狀態的核心項目一模一樣,不管 Lookahead 長怎樣,全都合併成同一個狀態」。
舉個例子,假設有:
- 狀態 A:
- 狀態 B:
你看!Lookahead 都長一樣,所以就合併變成:
爽吧!本來的 Table 長這樣:
用 化簡以後就變成: